Overview
The ability to automatically detect and track the surgical main areas in cataract surgery video will enable many transformational interventions. There are a number of applications that would benefit from this technology, including assistive interventions in teaching and performing surgery, and planning operational and logistical aspects of OR resources. However, obtaining the annotations needed to train AI models to identify and localize the surgical main areas is very challenging.
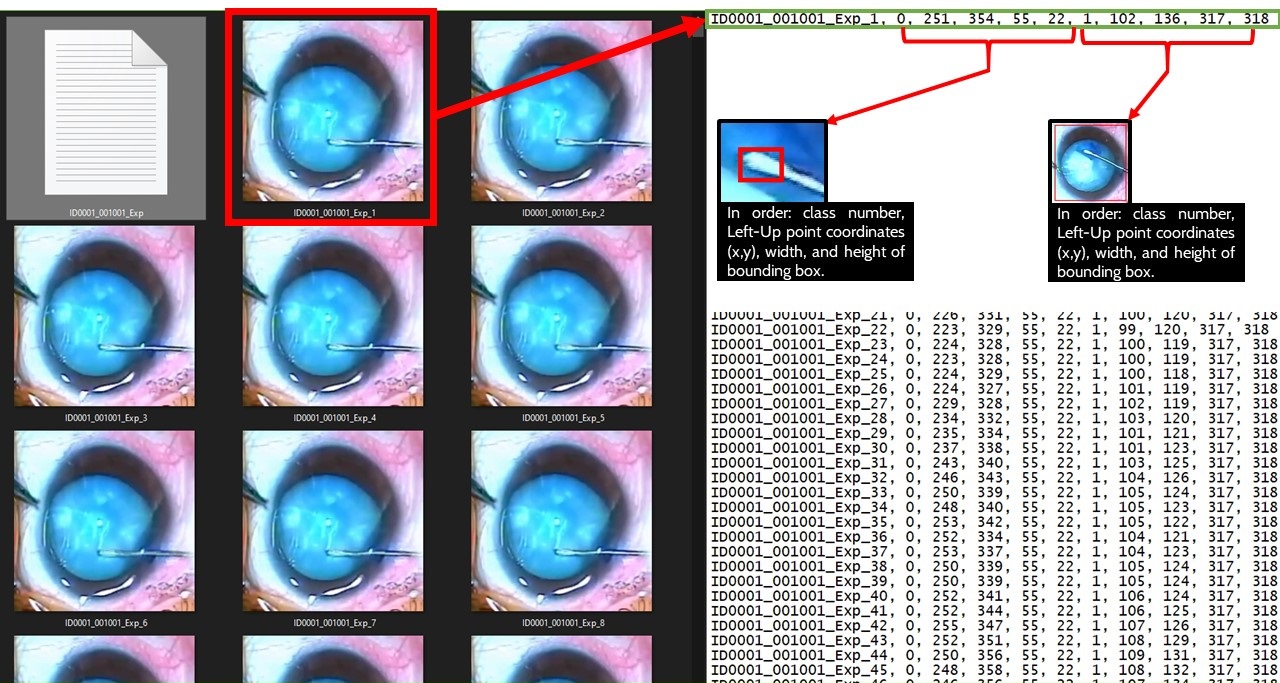
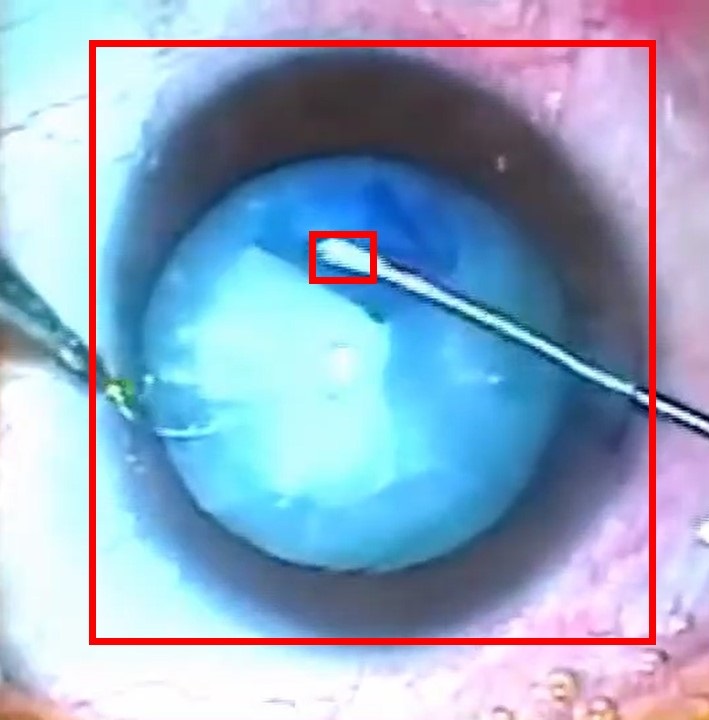
In this challenge, we invite the data scientist and researchers to leverage an annotated dataset as the input to train their machine learning models in order to detect and localize two main areas in capsulorhexis surgery with bounding boxes in the video frames. In simple terms, our problem is object tracking, where objects are the two main areas of surgery. The figure below shows these two areas. Once the challenge begins, we will provide you with a part of the ARFaT dataset, which includes images of video frames and related annotations. You will be instructed on how to upload your model’s results, as well as how ICRoM organizers will evaluate them. You are free to use any model you like, and any approach you find suitable.